西村屋トップページ>地球科学技術の耳学問(気楽にメッセ-ジ・ボードへ/検索エンジン)
2009年2月10日更新
=「数値モデル/計算コードのいろいろ」へのショートカット
=「地球シミュレータ」へのショートカット
「スカラー・プロセッサ」と「ベクトル・プロセッサ」
- - AMD x86_64 Opteron Quad Core:AMDサーバー向け/ウィキペディア
- Intel EM64T Xeon E54xx (Harpertown):インテル/ウィキペディア
- POWER6:IBM/ウィキペディア
- PowerPC 460:ウィキペディア
- PowerXCell 8i:IBM/ウィキペディア
スカラー・プロセッサといっても高速化のために進化しており、PlayStation3用に開発されたCELLなどベクトルプロセッサとどう違うのかだんだん分かりにくくなっている。また必ずしも汎用プロセッサとは限らなくなってもきており、今ではキャッシュ・ベースのプロセッサをスカラー・プロセッサと定義するのがよさそうだ。
-
Cray XT5 QC 2.3 GHz
Sun Blade x6420
IBM BladeCenter
Blue Gene/P Solution
Power 575, p6
それを越える大容量のデータを扱う計算のため、メモリ共有型の計算ノード同士をネットワークで結合するものを「メモリ分散型コンピュータ」という。
ちなみに、地球シミュレータの1ノードの共有メモリは面白いことに16 GB。SX-5以降の1/8以下である。どうして共有メモリを8倍の128 GBに、ノード数を1/8の80に減らさなかったのだろうか。
地球シミュレータセンターの話によると、流体計算が多いものについてはメモリよりもCPU数が必要なため、あえて1ノードを16 GBにしたという。ベクトルプロセッサは、キャッシュメモリを持たないので特に高性能のメモリ(FPLRAM、フルパイプラインメモリ)が要求され、その価格はずいぶんと高いため、費用対効果を考えて現在の構成となったようだ。
「レーテンシ(遅れ時間)」とは、データが送信元を出て、受信先に届くまでの時間をいう。当然、到着が送信元に確認されなければならない。
「バンド幅(データ転送性能)」とは、どのくらいのデータ量を単位時間内に送れるかというもの。
両者を水道管に例えると、パイプの長さ(短ければ早い)がレーテンシで、パイプ直径がバンド幅。
=>STREAMベンチマークテスト(Sustainable Memory Bandwidth in High Performance Computers、キャッシュの再利用ができないようにデータのサイズが調整されている)/SPEC200ベンチマークテスト
=>HPC Challenge/Result)
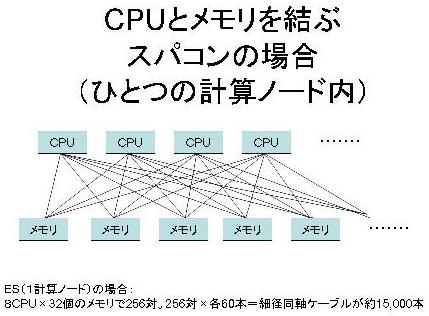 まず、ひとつのノードの中に着目してみよう。地球シミュレータの1ノード内には8つのプロセッサ(うちひとつはリモートアクセス制御/入出力用のプロセッサ)と、32個のメインメモリ(主記憶ユニット)がある。
まず、ひとつのノードの中に着目してみよう。地球シミュレータの1ノード内には8つのプロセッサ(うちひとつはリモートアクセス制御/入出力用のプロセッサ)と、32個のメインメモリ(主記憶ユニット)がある。普通のパソコンでは、メモリやCPUなどの各要素間の通信をひとつのバスで兼ねる“バス方式”が使われている。それだと、メモリからCPUへのデータ読み込みに時間が掛かってしまう。そこでスカラー・プロセッサではデータを高速のキャッシュから読み込むことで、わざわざメモリまで読みに行かずに済ませる。
ところが大規模計算ではデータが大きすぎてキャッシュに収まらないため、いちいち共通バスを介してメモリからデータを読み込まなければならない。つまりプロセッサの性能がいくらよかろうと、上記レーテンシとバンド幅で計算機の実効速度が決まってしまうわけである。
そこで、地球シミュレータでは、1ノード内の各プロセッサと各メインメモリを1つの共通バスで接続する代わりに、なんと1対1で直接接続している。ということは8プロセッサ×32メモリ=256対の接続が必要なのだが、高速化のため、一対の接続には1本のケーブルではなくソーメンの糸が60本束ねられたような細径同軸ケーブル(1本の長さ70cm、断面が0.66mm×0.85mmの楕円形)が使用されている。その結果、合計約15,000本の細径同軸ケーブルが使用されている。それによってノードあたりのデータスループット(バンド幅)が256 Gバイト/秒となっている。
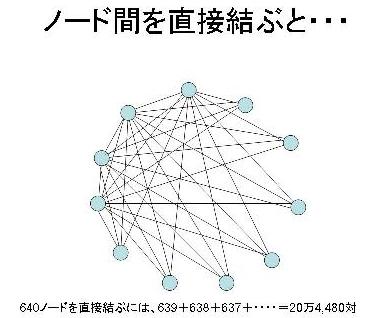 次にノード間のネットワーク接続を考えよう。上記と同様の考え方で、640ノード間を1対1で直接接続するにはいったい何本のケーブルが必要だろうか?
次にノード間のネットワーク接続を考えよう。上記と同様の考え方で、640ノード間を1対1で直接接続するにはいったい何本のケーブルが必要だろうか?640ノードを直接一対一結合するには、639+638+637+・・・・=639*640/2=204,480対という膨大な組み合わせになり、そのひとつひとつのノード間接続を高速化するために後述のような多分割を行わなければならないので、敷設すべきケーブルが実現不可能な本数になってしまう。
その代わりに用いられたのが「単段クロスバー結合」。640×640のクロスバースイッチ一つ(単段)と640ノードを結ぶもの。これだと直接結合と違って必ず経由が必要となる(間接網)が、640組の接続で済み、どこのノードに行くにも1ホップでいける。
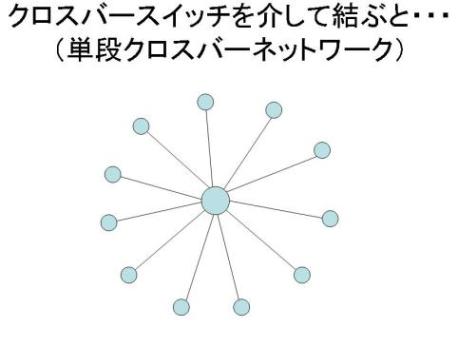
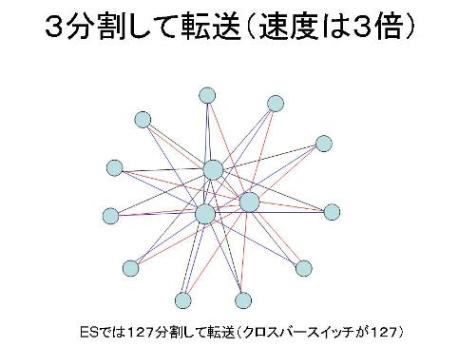
640×640のクロスバースイッチの代わりに例えば16×16のクロスバースイッチを多段にすることによっても同様のことが可能だが、それだけレーテンシ(遅れ時間)が増大することになる。
1:640の通信はいったいどうやって実現するのだろうか? 通信ライブラリ(MPI:message passinng interface)というプログラムによって、一組のノード間でデータが相手に渡ると、送り元と送り先が次の動作は別のノードと組を作り転送する。ネズミ算式に転送先が増える事になるが、これらは不思議なことに同時動作可能という。どう組み込まれているのかは、秘中の秘だそうだ。
さて、実際の地球シミュレータではノード間のバンド幅(転送速度)を極限まで高めるため、ノードとクロスバースイッチの間をなんと128分割して転送する。1本あたり1Gビット/秒の転送レートなので、128本では物理的に128Gビット/秒(=16Gバイト/秒)となる。データ品質確保のためECC(Error Correction Code)付とした結果、ノード間の転送速度は12.3 Gバイト/秒(双方向)となる。
以上の意味合いはお分かりだろうか? つまりレーテンシを極小にするため、任意のノード間を1ホップで接続する640×640クロスバー結合とした。さらにバンド幅を大きくするため、128分割にしたという、まさに力技としかいいようのない方法で高性能を達成しているわけである。
その結果、システム全体としてどうなったかというと、データ用128本のほか制御用2本が必要なので、合計130本がそれぞれ130のクロスバー・スイッチを経由して他のノードと結合され、その結果、ケーブル総数は130本×640ノード=83,200本ということになる。
640組のノード間において、あるノードは他のノード1つにしかデータ転送できず、データを受ける相手のノードは他にデータ転送できない。このため、同時に行われるデータ転送は320組となる。その結果、ネットワーク全体としてのスループットは、12.3Gバイト/秒×320×2(双方向)=約8Tバイト/秒という、とてつもないネットワーク。
地球シミュレータは中央部を128台のデータスイッチユニットが占めるよう配置されており、全ノード間を繋ぐケーブル類は総延長2400km、総重量140tにも達している。
単段クロスバー結合可能なノード数は原理的には640以上も可能であるが、現在のシステム構成では640以上には増やせない。
伝送路は、メタリックなのでノイズが載ることを想定しており、128台のイクスチェンジャの1台が故障しても大丈夫な設計になっている。
地球シミュレータの開発当時、CPUもメモリも電気信号で動作するので、それを光に変換してもあまり費用対効果が出ないとの判断だったとのこと。ただし電線だから一種のアンテナとなってしまうので、雑音(雑電波)を受けないよう、蛍光灯すらも壁の外の蛍光を屋内に導入する特殊なものを用いるなどさまざまにシールドしている。
実際、当時としてはどの程度の製品が存在したのだろうか。ネットで検索すると、2002年の「PRIMEPOWER HPC2500」の双方向16Gバイト/秒があり、これは地球シミュレータの(128本束ねた)物理上の転送速度と同じ。
ETHERなどシリアル伝送では、10Gビット/秒が最高なので16Gバイト/秒を達成するに13本束ねている。地球シミュレータの128本に比べたらずいぶん少ないのだが、とんでもなく高いものにつくらしい。しかも、計算はノード内で電気で行われる訳だから電気・光間の変換が伴う。これに要する時間は、電気のみに比べ純増となってレーテンシが増大する。このため、地球シミュレータの開発当時としては光インターコネクトを採用できなかったわけである。
=>TOP500 Supercomputer Sites>ランキング・リスト
=>スーパーコンピューティングの将来(牧野淳一郎)
=>☆たるさんのパソコンフィールド
「カオス」と「予測可能性の限界」と「アンサンブル予報」
この場合、初期値をわずかに変えていくつかの予測計算を行ってその結果を統計処理することで確率的な予報を行うことができる。この方法を「アンサンブル予報」という。初期値にどのような摂動を加えるかが重要な鍵となっている。
このカオスのせいで、異常な猛暑や寒波の原因とされるブロッキング現象の予測は困難との研究結果もある。
海洋については大気のようなカオスは現れにくい。したがって大気海洋結合モデルで計算すると年内変動には当たり外れはあっても、数年~数十年というトレンドとしてはそれなりの予測が可能という考えがある。あるいは遥かに長期の予測を行えば海洋でもカオスが起こるのかもしれない。
この補完方法には力学法則的な合理性はなく、大気モデルや海洋モデルを用いて補完する方法を「データ同化」という。データ同化には次項のとおりいくつかの手法がある。
「再解析データセット」/「再解析プロダクト」と呼ばれるデータセットには、異なる観測手段のデータを誤差補正などを行いながら幾何学的に補完したデータセットの場合と、データ同化した場合がある。
補正するに従ってモデルの解と観測データとの誤差を減らすように修正していく方法を「カルマン・フィルター法」という。過去の情報を時間軸の順方向に反映している。この方法と未来の情報を解析場に反映させるRTSスムーザーを組み合わせた「カルマンフィルター・スムーザー」は、次のアジョイント法/四次元変分法と一致する。
基礎方程式を時間的にフォワード積分し、次にその随伴方程式(アジョイント方程式)をバックワード積分することを繰り返して修正していく方法を「アジョイント法/四次元変分法」という。過去の情報だけでなく未来の情報も解析場に反映させている。
四次元変分法では逆解析が可能となるので、メカニズムの解明や観測システム配置の最適化に使うことも可能。長期予測の初期値としても短周期成分が除去されることとなるので最適である。
データ同化には2系列がある。
・線形最小分散推定:最適内挿法、カルマンフィルター(時間前方フィルター)、カルマンフィルター・スムーザーという順に精度が向上する。
・最尤(さいゆう)推定:3次元変分法、アジョイント法/4次元変分法という順に精度が向上する。
=>海と気候の用語集(見延庄士郎さんのサイトより)【相互リンク】
西村屋トップページ>地球科学技術の耳学問(気楽にメッセ-ジ・ボードへ/検索エンジン)